

Karandaaz and BOP Collaborate to Empower Female Entrepreneurship
April 10, 2025
MyAlice and Unity Retail Transforming Ecommerce Through Partnership
April 10, 2025
If you are a tech enthusiast and follow the LLM world, you must have heard the term “Reasoning Models”! Especially in relation to the recent buzzing news about DeepSeek-R1 (where R stands for Reasoning). So, what are these Reasoning Models and what can they do what existing models like ChatGPT 4o, Claude Sonnet or Google Gemini can’t do?
In September 2024, OpenAI unveiled its first reasoning model o1, marking a significant breakthrough in the evolution of artificial intelligence. Unlike traditional LLMs that rely on rapid statistical predictions, these reasoning models tackle complex questions by breaking them down into a series of logical steps through a chain-of-thought process. Leveraging reinforcement learning (RL), o1 has been trained to excel in fields such as mathematics, science, and coding—performing at the level of PhD students in physics, chemistry, and biology, while even surpassing them in math and coding. By learning to identify and correct its mistakes, simplify intricate problems, and adapt its strategies dynamically, the o1 model mimics human problem-solving in a way that dramatically enhances its reasoning capabilities.
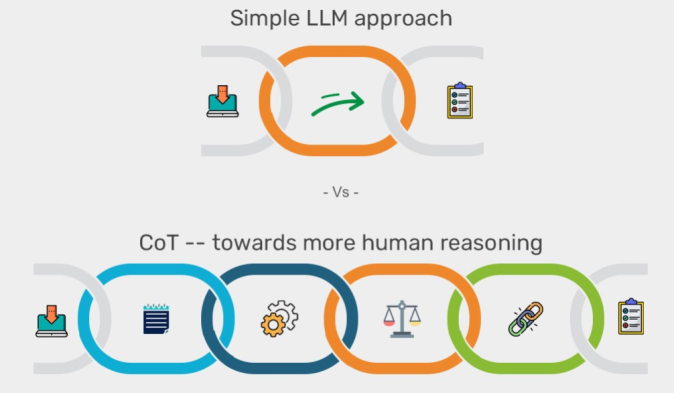
Image credit : fundingminds.com
Although, there is currently no standard definition of term “Reasoning”, however, it can be described as the process of answering questions that require complex and “step-by-step” thinking. For example, if I ask you about the capital of France, you will respond almost immediately with “Paris”, why? Because the question doesn’t involve any complex thinking or reasoning and is merely a recollection from the memory. But What if I ask you that “If a train is traveling at the speed of 60 MPH, how much distance it will it cover in 3 hours?”. You won’t answer immediately and will take a moment to think about the calculations involved. In your mind, you will use the knowledge regarding the relationship between speed and distance and hopefully, with some steps of mental math, you will give the answer as 180 Miles.
This process of thinking step by step and reason about a question can be done by most modern LLMs like ChatGPT 4o, Claude and Llama etc. However, this capability is only limited to simple problems that require very basic reasoning or computation.
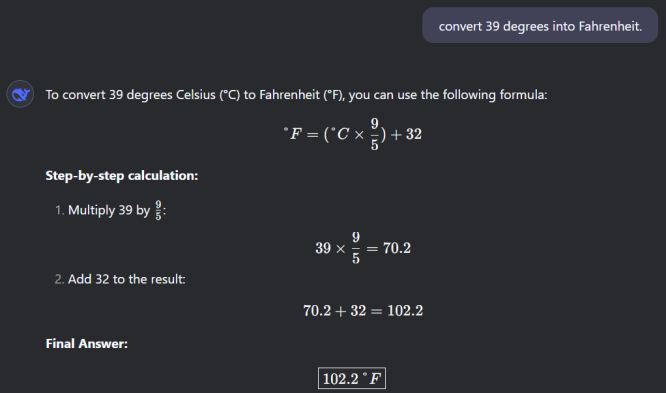
Figure : Output of DeepSeek-V3 Model

Figure : Output of DeepSeek-R1 Model
If you want LLMs to solve some complex problems, there needs to be a way to guide LLMs to “Think Before They Speak!!”. And that’s where these reasoning models come into the play.
So how do we give LLMs this ability to think? Most modern reasoning models like OpenAI’s o1 and DeepSeek R1 include a “reasoning” or “Thinking” process as part of their response. Whether or not LLMs actually “Think” or not is a separate discussion. For this article, let’s just call this capability as Thinking or reasoning capability.
There are two ways in which LLMs can be trained to reason. The first method can be to explicitly build this capability within the response of the model. The second method is to run multiple iterations before returning the response to the user. Most probably, OpenAI’s o1 follows this approach, however, it doesn’t show all the reasoning steps that happen behind the scenes.
So, let’s see what are two most talked about reasoning models available today and how do they compare in technology?
OpenAI’s o1
Building on top of principle of chain‐of‐thought reasoning, OpenAI’s o1 model distinguishes itself by integrating dedicated “reasoning tokens” that allow it to decompose problems into a series of intermediate, verifiable steps. Instead of simply predicting the next word, o1 uses reinforcement learning both during training and at inference to refine these multi-step reasoning processes. This deliberate “thinking” phase—where additional test‑time compute is allocated—has yielded a reported 34% reduction in error rates on complex tasks, notably in advanced mathematics, coding, and scientific research. A specialized training dataset, optimized for logical coherence, is used during the training phase to enable o1 to self‐correct and better manage ambiguous or multi-faceted queries, setting it apart from earlier models like GPT‑4o. However, o1 does not disclose the reasoning steps to the end user but instead only displays the final output. Also due to the inherent architecture of the model, the computation required as well as the output tokens generated for a single answer are manifolds compared to 4o making o1costlier to access. As per OpenAI’s current pricing details, o1 costs $15/ million input tokens and $60/ million output tokens compared to $2.5/ million input and $1.25/ million output tokens for GPT-4o.
DeepSeek-R1
DeepSeek is not a new player in this field with state of the art LLMs. Their coding LLM named DeepSeek-Coder-V2 released in Jun 24 was beating all major opensource and proprietary LLMs in coding task. In December 2024, they released their flagship LLM DeepSeek-V3 which was beating all open source LLM in all major evaluation metrics and was comparable in performance to most proprietary LLMs like ChatGPT-4o and Claude 3.5 Sonnet.
The launch of DeepSeek-R1 generated ripples in LLM world primarily due to three major reasons.
-
- First, R1 LLM is (approximately) less than half the size (in terms of number of parameters), with 671 billion parameters and is able to give performance comparable to OpenAI o1. Also, the model was able to generate response with just 5% of the total parameters active during the inference time, making it faster and cheaper than o1. API cost for R1 is almost 21X cheaper than o1.
Another important thing to note is that the final training run of DeepSeek-R1 was on a cluster with 2048 NVIDIA H800 GPUs, which are the older generation GPUs. DeepSeek was able to carry out training on the older generation of GPUs by coding the training pipeline in low level language. This capability at such large scale generated immense interest in the AI community (and may have contributed towards fall of Nvidia stocks since DeepSeek proved that large scale training is possible with slightly low end and a smaller number of GPUs contrary to the hype worldwide)
- First, R1 LLM is (approximately) less than half the size (in terms of number of parameters), with 671 billion parameters and is able to give performance comparable to OpenAI o1. Also, the model was able to generate response with just 5% of the total parameters active during the inference time, making it faster and cheaper than o1. API cost for R1 is almost 21X cheaper than o1.
-
- Secondly, the complete model is open-source and free to download, finetune and use by anyone. This gives huge support to organizations looking for private deployments as well as research community to experiment, learn and build.
- Lastly, the “Aha!” approach to utilize intuitive reinforcement learning technique for model training makes the approach state-of-the-art. DeepSeek’s R1 pipeline enabled models to reason step-by-step without relying on large datasets of labeled reasoning examples. Their results, demonstrated in the R1-Zero experiment, show that reinforcement learning alone can develop advanced reasoning skills, avoiding the need for extensive supervised training. R1-Zero learned to produce detailed reasoning steps, check its own solutions, and spend more computation time on harder problems. Remarkably, these behaviors were not programmed explicitly but emerged during training.
As per DeepSeeks’s current pricing details, R1 costs $0.14/ million input tokens and $2.19/ million output tokens compared to $15/ million input and $60/ million output tokens for OpenAI’s o1. And just recently, DeepSeek announced a further 30% discount on both reasoning and chat models.
Where to use Reasoning Models?
Reasoning models are designed to be good at complex tasks such as solving complex puzzles, advanced math problems and challenging coding tasks. They are not meant to be used for simple tasks like summarization, classification, translation or basic knowledge questions. In fact, using reasoning models for such tasks is inefficient and expensive. Since, such models are designed to “Think”, they eventually end up “Overthinking” for simpler tasks, generating very verbose responses and resultantly may give inaccurate answers to simpler questions while also being costly due to large number of tokens being generated.
Reasoning models are super-efficient for deductive or inductive reasoning tasks. The are trained to generate response as “Chain of Thoughts” by breaking down the question into a series of linked tasks. Thus allows these reasoning models to be suitable for scenarios like research, where complex decision making or reasoning is involved. This ability of reasoning or thinking enables these models to generalize well for novel problems compared to simple LLMs. Here are some of the key use cases where these advanced reasoning models shine:
-
Advanced Scientific and Mathematical Problem Solving
These models excel at tasks requiring multi-step logical deduction. For instance, in scientific research or higher-level mathematics, they can decompose complex proofs or equations into a series of verifiable intermediate steps. Researchers can leverage this chain-of-thought capability to explore hypotheses, validate calculations, and even generate novel approaches to longstanding problems.
-
Complex Coding and Debugging Tasks
In the realm of software development, reasoning models offer significant advantages. Models like o1, with their dedicated reasoning tokens, can break down intricate coding problems, propose multi-step debugging solutions, and assist in writing robust code. DeepSeek-R1’s cost-efficient architecture makes it a strong candidate for organizations that need to run intensive code analysis without incurring prohibitive expenses.
-
Strategic Decision Making and Scenario Analysis
For industries like finance, logistics, and operations research, complex decision-making often involves evaluating multiple layers of causality and risk. These reasoning models can simulate “what-if” scenarios, weighing various factors and outcomes systematically. This makes them invaluable tools for strategic planning, risk assessment, and dynamic forecasting in volatile markets.
-
Legal Analysis and Policy Formulation
In law and public policy, arguments often rest on nuanced reasoning and the interpretation of complex statutes. Reasoning models can assist legal professionals by parsing multifaceted cases into logical segments, helping to outline arguments or predict potential interpretations of legislative texts. Their ability to generate a chain of reasoning also aids in exploring precedents and drawing correlations between seemingly disparate cases.
-
Educational Tools and Personalized Tutoring
For educational platforms, incorporating reasoning models can transform how concepts are taught. By breaking down problems into smaller, digestible steps, these models help learners understand the reasoning behind solutions rather than just receiving the final answer. This approach can be particularly effective in STEM education, where the process is as important as the result.
-
Research and Innovation in AI and Beyond
Given their open-source nature and cost efficiencies, models like DeepSeek-R1 open up new avenues for academic and industry research. They serve as experimental platforms for developing next-generation AI systems, enabling a deeper understanding of how layered reasoning can be harnessed to improve overall model performance.
Conclusion
Reasoning models represent a significant leap forward in how artificial intelligence tackles complex, multi-step tasks. By integrating a deliberate “thinking” phase into their processing pipelines, these models reduce errors in intricate problem solving and expand the range of applications—from advanced mathematics and scientific research to coding, legal analysis, and strategic decision-making.
However, it’s important to note that these capabilities come with trade-offs in terms of response time and cost, which makes them best suited for tasks where detailed reasoning is essential rather than for simple, straightforward queries.
About the writer: Dr. Usman Zia is Director Technology at InnoVista and Associate Professor at the School of Interdisciplinary Engineering and Sciences (SINES), National University of Sciences and Technology (NUST), Pakistan. His research interests are Large Language Models, Natural Language Processing, Deep Learning and Machine Learning. He has authored numerous publications on language generation and machine learning. As an AI enthusiast, he is actively involved in several projects related to generative AI and LLMs.



{kind=link}
{kind=link}
{kind=link}